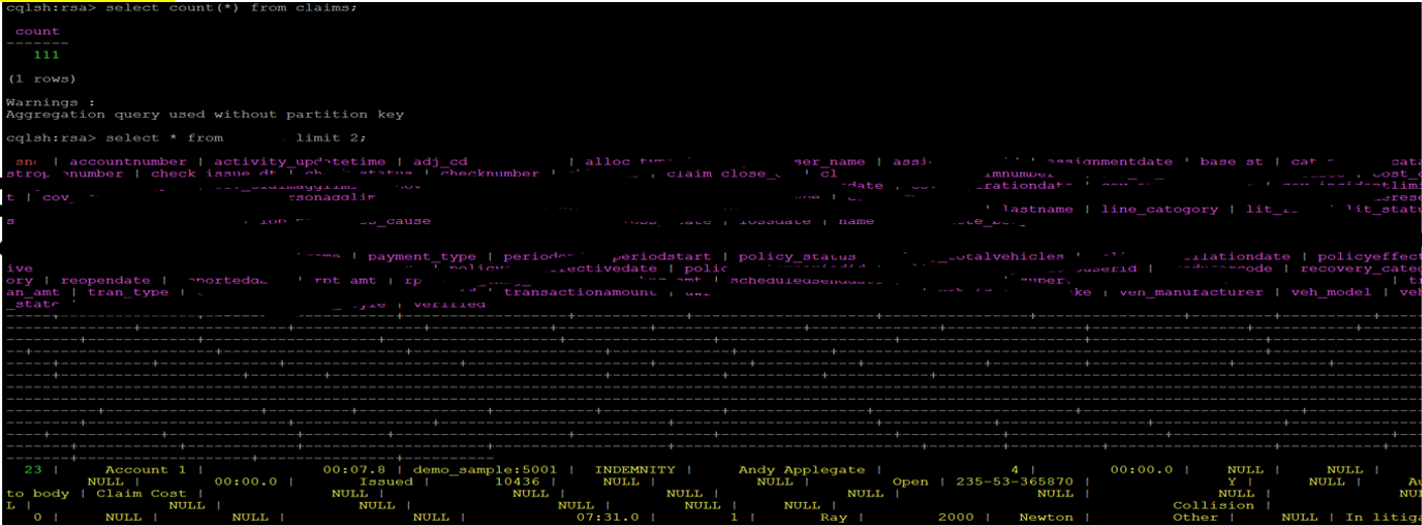
Objective: To perform the integration between the below components
and perform the data ingestion to Cassandra tables.
- zookeeper-3.4.10
- kafka_2.12-1.0.0.tgz
- scala-2.11.6.tgz
- spark-2.2.1-bin-hadoop2.7.tgz
- apache-cassandra-3.0.14-bin.tar.gz
- Component Integration testing
Prerequisite:
Kafka:
Kafka-Zookeeper:
To start the kafka application we need to first start the zookeeper then the kafka server.
To start the zookeeper:
bin/zkServer.sh start
To start the kafka server:
bin/kafka-server-start.sh config/server.properties
Step 1-> Topic creation:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic bivibes.sample
With the above command a Kafka topic named “bivibes.sample” has been created for this project.
Step 2:→Topic Listing:
bin/kafka-topics.sh --list --zookeeper localhost:2181
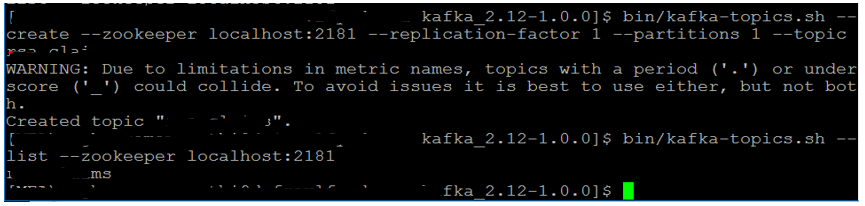
This step will list the topic that we created.
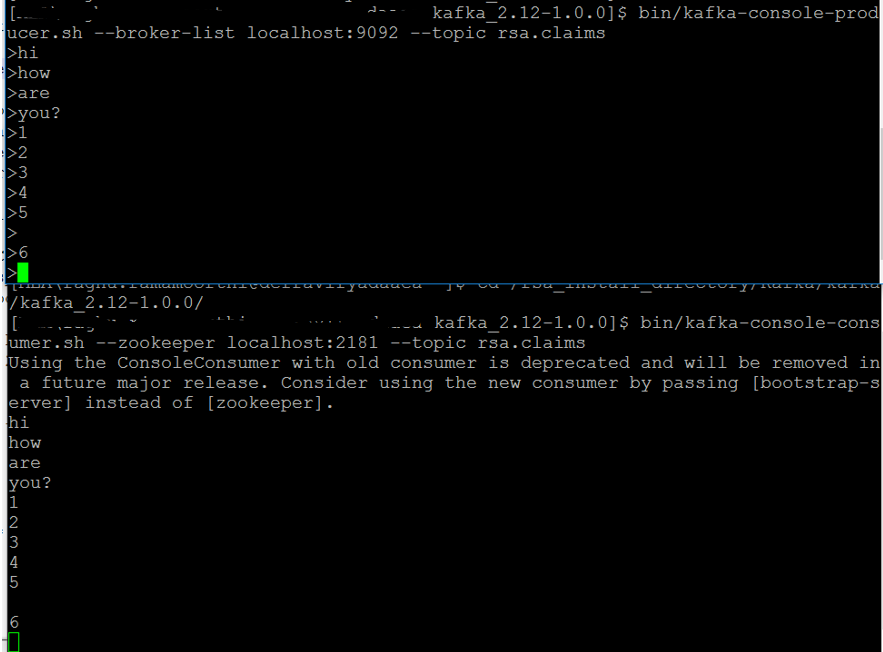
Step 3: KAFKA inbuilt producer consumer testing
NB: This step is just for testing purpose
To test this out open two separate terminals and in one terminal type the command to invoke the inbuilt producer and in the other terminal type the command to invoke the inbuilt consumer. Then type something in the producer terminal; you can see that that is printed in the consumer terminal as well. Side by side both terminal screenshot is given below.
Kafka Console Producer:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic bivibes.sample
Kafka Console consumer:
bin/kafka-console-consumer.sh --broker-list localhost:9092 --topic bivibes.sample
Sample Data Ingestion
Now that we have tested out Kafka functionality in the step 3 of first section; we are about to do the actual data ingestion to Casandra. So the data flow is as given below:
Source Csv→ KAFKA Producer→ Topic→ Kafka consumer→ Spark Streaming→ Cassandra
To perform the data ingestion; we have created a custom producer in java and the consumer application code is written in pyspark.
Producer application we used:
import csv
from kafka import KafkaProducer
import json
import os
#Spark
from pyspark import SparkContext, SparkConf
from pyspark.sql.context import SQLContext
from pyspark.sql import HiveContext, Row
from pyspark.sql.types import StringType, StructType, StructField
#Spark Streaming
from pyspark.streaming import StreamingContext
#Kafka
from pyspark.streaming.kafka import KafkaUtils
#json parsing
import re
import sys
from uuid import uuid1
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-8-assembly_2.11-2.2.0 pyspark-shell'
os.environ['PYTHONPATH'] = '/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/:/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/pyspark_cassandra.zip'
topic = sys.argv[1]
inputfilepath = sys.argv[2]
producer = KafkaProducer(bootstrap_servers='localhost:9092')
def sendMessage(msg):
records = msg.collect()
co = msg.count()
print('count is ',co)
if co > 0:
for record in records:
producer.send(topic,json.dumps(record).encode('utf-8'))
#producer.send(topic,str(records))
producer.flush()
print(record)
else:
print('no data to produce')
def main():
sc = SparkContext(appName="KafkaProducer")
ssc = StreamingContext(sc, 1)
FileStream = ssc.textFileStream(inputfilepath)
rdd = FileStream.map(lambda l:re.sub(',','|',l)).map(lambda li: li.split('\t'))
#rdd = FileStream.map(lambda li: li.split(','))
#rdd.pprint()
FileStream.foreachRDD(sendMessage)
ssc.start()
ssc.awaitTermination()
if __name__ == "__main__":
main()
******************************************************************************************
Consumer application we used:
import os
from pyspark import SparkContext, SparkConf
from pyspark.sql.context import SQLContext
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType, StructType, StructField
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import sys
#import aimodule
#import PythonHttpClient
sys.path.append('/bivibes_install_directory/Modelling/Final/')
#import json
#from uuid import uuid1
#import pyspark_cassandra
#from pyspark_cassandra import CassandraSparkContext, saveToCassandra
os.environ['PYSPARK_SUBMIT_ARGS'] = '--packages org.apache.spark:spark-streaming-kafka-0-8-assembly_2.11-2.2.0 pyspark-shell'
os.environ['PYTHONPATH'] = '/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/:/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/pyspark_cassandra.zip'
topic = sys.argv[1]
#inputfilepath = sys.argv[2]
def main():
conf = (SparkConf().setAppName("spark-streaming"))
sc = SparkContext.getOrCreate();
# sc.setLogLevel("WARN")
ssc = StreamingContext(sc, 1)
#scc = CassandraSparkContext(conf=conf)
kafkaStream = KafkaUtils.createStream(ssc, 'localhost:2181', 'spark-streaming', {topic:1})
kafkaStreamRdd = kafkaStream.map(lambda x: x[1])
kafkaStreamRdd.foreachRDD(process)
ssc.start()
ssc.awaitTermination()
sc.stop()
def process(kafkaStreamRdd):
# Convert RDD[List] to DataFrame
print('converting to dataframe')
sc = SparkContext.getOrCreate();
sqlctxt = SQLContext(sc)
delim = ','
count = kafkaStreamRdd.count()
if count > 0:
newrdd = kafkaStreamRdd.map(lambda l: l.replace('"','')).map(lambda l: l.replace('[','')).map(lambda l: l.replace(']','')).map(lambda l: l.split(delim))
schemaString = "colname1,colname2..etc"—depending up on the input file you use
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split(delim)]
schema = StructType(fields)
#print(len(fields),'length of fileds in DataFrame &&&&&&& ')
newrdd1 = newrdd.filter(lambda line : line != schemaString.split(','))
newrddDataFrame = sqlctxt.createDataFrame(newrdd1,schema)
cassandraWrite = newrddDataFrame.write.format("org.apache.spark.sql.cassandra")
#save dataframe in cassandra table
cassandraWrite.options(table="sample_data", keyspace="bivibes").mode("append").save()
else:
print('no data received')
if __name__ == "__main__":
main()
Place the below three in the Linux box using winscp:
- Producer.py
- sparkConsumer.py
- Input.csv
Step 4.1:
Invoke the custom KAFKA custom producer command to read the input data and produce to topic we created:
Command used:
java -jar prod.jar bivibes.sample /bivibes_install_directory/input
/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/spark-submit --jars /bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/jars/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar --driver-class-path /bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/jars/spark-streaming-kafka-0-10-assembly_2.11-2.2.0 /bivibes_install_directory/kafkaProd.py bivibes.sample /bivibes_install_directory/input
bivibes_sample→ topic we created
directory of the input file→/bivibes_install_directory/input

Producer has successfully sent the messages to topic.
Step 2: Spark streaming to consume the data from the topic:
In step 1 we have tested that KAFKA custom producer has produced the input data to topic. In this step we have to invoke the spark streaming to consume the data that is being sent from the topic. That can be done using the below command:
/bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/bin/spark-submit --jars /bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/jars/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar --driver-class-path /bivibes_install_directory/spark/spark-2.2.0-bin-hadoop2.7/jars/spark-streaming-kafka-0-8-assembly_2.11-2.2.0 /bivibes_install_directory/sparkConsumer.py bivibes.sample
The above green highlighted are the input parameters for this command
After running the above command open another terminal and run the command to produce the data to topic again.
java -jar prod.jar bivibes.sample /bivibes_install_directory/input
The above green highlighted are the input parameters for this command.
Once you produce the data by running the above command you can see the below data coming in the first consumer window; since we have given the code to show the data for testing purpose.
Step 3: Connect to Cassandra and create the table
Navigate to the path just before bin and type the below commands:
bin/cqlsh

Step 3.1:
Type the below sql commands one by one. Don’t forget to append semicolon. (;)
#create keyspace
create keyspace bivibes WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 1 } AND DURABLE_WRITES = false;
#use keyspace
use bivibes;
#create table command:
Create table sample(--here give the column names along with the data type---);
ex: create table anzsample(id int PRIMARY KEY, name text, dept text);
NB: Now that we created the table in Cassandra we can write the data produced by Kafka to Cassandra. In the sparkConsumer.py file we have edited the code to write to the Cassandra table. PFB the code snippet form sparkConsumer.py file for writing the data. After editing this code repeat the step 2 so that kafka producer will again produce the data and spark streaming will consume the data and write the data to Cassandra.
cassandraWrite.options(table="sample_data", keyspace="bivibes").mode("append").save()
Step 3.2: To view the data in the Cassandra table after step 3.1:
Connect to Cassandra and just run the sql
Select * from sample