From today on wards I will start writing on my learning and experiment on Next gen data ,
its Integration & Data Visualization
What is Big Data?
Global digital content created will increase some 30 times over the next ten years – to 35 zettabytes.Big data is a popular, but poorly defined marketing buzzword. One way of looking at big data is that it represents the large and rapidly growing volume of information that is mostly untapped by existing analytical applications and data warehousing systems. Examples of this data include high-volume sensor data and social networking information from web sites such as FaceBook and Twitter. Organizations are interested in capturing and analyzing this data because it can add significant value to the decision making process. Such processing, however, may involve complex workloads that push the boundaries of what is possible using traditional data warehousing and data management techniques and technologies.
In addition, Big Data has popularized two foundational storage and processing technologies: Apache Hadoop and the NoSQL database.
Big Data has also been defined as any data which satisfies the characteristics of the five “V”s: Volume, Velocity, Variety, Veracity and Value. These become a reasonable test to determine whether you should add Big Data to your information architecture.
Volume. The amount of data. While volume indicates more data, it is the granular nature of the data that is unique. Big Data requires processing high volumes of low-density data, that is, data of unknown value, such as twitter data feeds, clicks on a web page, network traffic, sensor-enabled equipment capturing data at the speed of light, and many more. It is the task of Big Data to convert low-density data into high-density data, that is, data that has value. For some companies, this might be tens of terabytes, for others it may be hundreds of petabytes.
In addition, Big Data has popularized two foundational storage and processing technologies: Apache Hadoop and the NoSQL database.
Big Data has also been defined as any data which satisfies the characteristics of the five “V”s: Volume, Velocity, Variety, Veracity and Value. These become a reasonable test to determine whether you should add Big Data to your information architecture.
Volume. The amount of data. While volume indicates more data, it is the granular nature of the data that is unique. Big Data requires processing high volumes of low-density data, that is, data of unknown value, such as twitter data feeds, clicks on a web page, network traffic, sensor-enabled equipment capturing data at the speed of light, and many more. It is the task of Big Data to convert low-density data into high-density data, that is, data that has value. For some companies, this might be tens of terabytes, for others it may be hundreds of petabytes.
Velocity. A fast rate that data is received and perhaps acted upon. The highest velocity data normally streams directly into memory versus being written to disk. Some Internet of Things (IoT) applications have health and safety ramifications that require real-time evaluation and action. Other internet-enabled smart products operate in real-time or near real-time. As an example, consumer e-commerce applications seek to combine mobile device location and personal preferences to make time sensitive offers. Operationally, mobile application experiences have large user populations, increased network traffic, and the expectation for immediate response.
Variety. New unstructured data types. Unstructured and semi-structured data types, such as text, audio, and video require additional processing to both derive meaning and the supporting metadata. Once understood, unstructured data has many of the same requirements as structured data, such as summarization, lineage, auditability, and privacy. Further complexity arises when data from a known source changes without notice. Frequent or real-time schema changes are an enormous burden for both transaction and analytical environments.
Veracity: refers to the messiness or trustworthiness of the data. With many forms of big data, quality and accuracy are less controllable, for example twitter posts with hashtags, abbreviations, typos and colloquial speech. Big data and analytics technology now allows us to work with these types of data. The volumes often make up for the lack of quality or accuracy.But all the volumes of fast-moving data of different variety and veracity have to be turned into value! This is why value is the one V of big data that matters the most.
Value refers to our ability turn our data into value. It is important that businesses make a case for any attempt to collect and leverage big data. It is easy to fall into the buzz trap and embark on big data initiatives without a clear understanding of the business value it will bring.
Traditional Information Architecture Capabilities
In the illustration, you see two data sources that use integration (ELT/ETL/Change Data Capture) techniques to transfer data into a DBMS data warehouse or operational data store, and then offer a wide variety of analytical capabilities to reveal the data. Some of these analytic capabilities include: dashboards, reporting, EPM/BI applications, summary and statistical query, semantic interpretations for textual data, and visualization tools for high-density data. In addition, some organizations have applied oversight and standardization across projects, and perhaps have matured the information architecture capability through managing it at the enterprise level.
Big Data Reference Architecture Overview
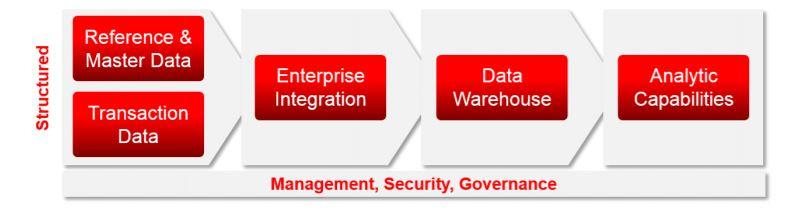
The key information architecture principles include treating data as an asset through a value, cost,
and risk lens, and ensuring timeliness, quality, and accuracy of data. And, the enterprise architecture
oversight responsibility is to establish and maintain a balanced governance approach including
using a center of excellence for standards management and training.
and risk lens, and ensuring timeliness, quality, and accuracy of data. And, the enterprise architecture
oversight responsibility is to establish and maintain a balanced governance approach including
using a center of excellence for standards management and training.
When Big Data is Added - Transformed Data Architecture:
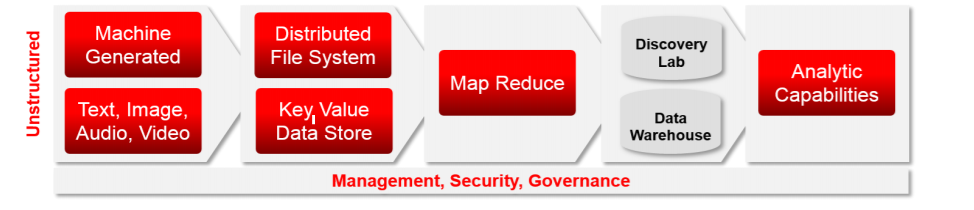
The defining processing capabilities for big data architecture are to meet the five V’s requirement.
Unique distributed (multi-node) parallel processing architectures have been created to parse these
large data sets. There are differing technology strategies for real-time and batch processing storage
requirements. For real-time, key-value data stores, such as NoSQL, allow for high performance,
index-based retrieval. For batch processing, a technique known as “Map Reduce,” filters data according
to a specific data discovery strategy. After the filtered data is discovered, it can be analyzed directly,
loaded into other unstructured or semi-structured databases, sent to mobile devices, or merged into
traditional data warehousing environment and correlated to structured data.
Reference Architecture for Big Data:
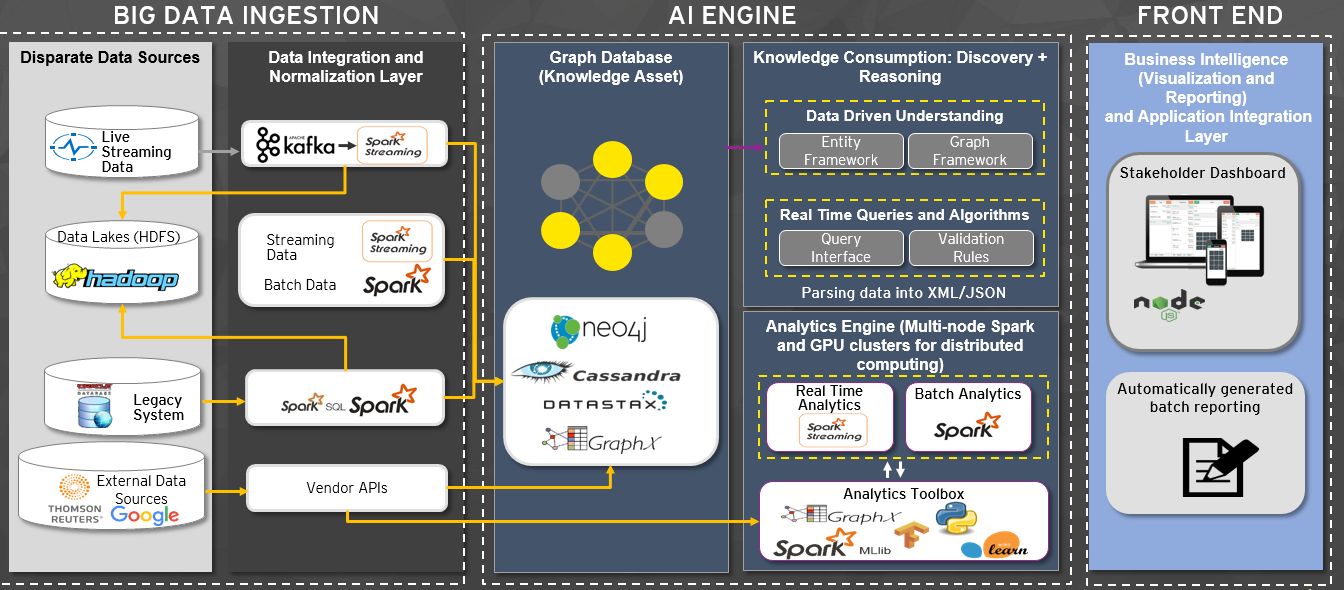
Big Data Architecture Patterns:
Unique distributed (multi-node) parallel processing architectures have been created to parse these
large data sets. There are differing technology strategies for real-time and batch processing storage
requirements. For real-time, key-value data stores, such as NoSQL, allow for high performance,
index-based retrieval. For batch processing, a technique known as “Map Reduce,” filters data according
to a specific data discovery strategy. After the filtered data is discovered, it can be analyzed directly,
loaded into other unstructured or semi-structured databases, sent to mobile devices, or merged into
traditional data warehousing environment and correlated to structured data.
Reference Architecture for Big Data:
Big Data Architecture Patterns:

IIn addition to the new components, new architectures are emerging to efficiently accommodate new storage, access, processing, and analytical requirements. First, is the idea that specialized data stores, fit for purpose, are able to store and optimize processing for the new types of data.
A Polygot strategy suggests that big data oriented architectures will deploy multiple types of data stores. Keep in mind that a polyglot strategy does add some complexity in management, governance, security, and skills.
Second, we can parallelize our data foundation for both speed and size, this is crucial for next-generation data services and analytics that can scale to any latency and size requirements. With this Lambda based architecture we’re now able to address fast data that might be needed in an Internet of Things architecture.
Third, Data pipelines that allow us to treat data events in a moving time windows at variable latencies; in the long run this will change how we do ETL for most use cases. The defining processing capabilities for big data architecture are to meet the five V’s requirements. Unique distributed (multi-node) parallel processing architectures have been created to parse these large data sets. There are differing technology strategies for real-time and batch processing storage requirements. For real-time, key-value data stores, such as NoSQL, allow for high performance, index-based retrieval. For batch processing, a technique known as “Map Reduce,” filters data according to a specific data discovery strategy. After the filtered data is discovered, it can be analyzed directly, loaded into other unstructured or semi-structured databases, sent to mobile devices, or merged into traditional data warehousing environment and correlated to structured data. Many new analytic capabilities are available that derive meaning from new, unique data types as well as finding straightforward statistical relevance across large distributions. Analytical throughput also impacts the transformation, integration, and storage architectures, such as real-time and near-real time events, ad hoc visual exploration, and multi-stage statistical models. Nevertheless, it is common after Map Reduce processing to move the “reduction result” into the data warehouse and/or dedicated analytical environment in order to leverage existing investments and skills in business intelligence reporting, statistical, semantic, and correlation capabilities. Dedicated analytical environments, also known as Discovery Labs or sandboxes, are architected to be rapidly provisioned and deprovisioned as needs dictate. One of the obstacles observed in enterprise Hadoop adoption is the lack of integration with the existing BI ecosystem. As a result, the analysis is not available to the typical business user or executive. When traditional BI and big data ecosystems are separate they fail to deliver the value added analysis that is expected. Independent Big Data projects also runs the risk of redundant investments which is especially problematic if there is a shortage of knowledgeable staff.
A Polygot strategy suggests that big data oriented architectures will deploy multiple types of data stores. Keep in mind that a polyglot strategy does add some complexity in management, governance, security, and skills.
Second, we can parallelize our data foundation for both speed and size, this is crucial for next-generation data services and analytics that can scale to any latency and size requirements. With this Lambda based architecture we’re now able to address fast data that might be needed in an Internet of Things architecture.
Third, Data pipelines that allow us to treat data events in a moving time windows at variable latencies; in the long run this will change how we do ETL for most use cases. The defining processing capabilities for big data architecture are to meet the five V’s requirements. Unique distributed (multi-node) parallel processing architectures have been created to parse these large data sets. There are differing technology strategies for real-time and batch processing storage requirements. For real-time, key-value data stores, such as NoSQL, allow for high performance, index-based retrieval. For batch processing, a technique known as “Map Reduce,” filters data according to a specific data discovery strategy. After the filtered data is discovered, it can be analyzed directly, loaded into other unstructured or semi-structured databases, sent to mobile devices, or merged into traditional data warehousing environment and correlated to structured data. Many new analytic capabilities are available that derive meaning from new, unique data types as well as finding straightforward statistical relevance across large distributions. Analytical throughput also impacts the transformation, integration, and storage architectures, such as real-time and near-real time events, ad hoc visual exploration, and multi-stage statistical models. Nevertheless, it is common after Map Reduce processing to move the “reduction result” into the data warehouse and/or dedicated analytical environment in order to leverage existing investments and skills in business intelligence reporting, statistical, semantic, and correlation capabilities. Dedicated analytical environments, also known as Discovery Labs or sandboxes, are architected to be rapidly provisioned and deprovisioned as needs dictate. One of the obstacles observed in enterprise Hadoop adoption is the lack of integration with the existing BI ecosystem. As a result, the analysis is not available to the typical business user or executive. When traditional BI and big data ecosystems are separate they fail to deliver the value added analysis that is expected. Independent Big Data projects also runs the risk of redundant investments which is especially problematic if there is a shortage of knowledgeable staff.
No comments:
Post a Comment